数据编码格式
- RLP (Recursive Length Prefix),ETH1.0、执行层采用的编码方式
- SSZ (Simple Serialize),ETH2.0、共识层采用的编码方式
RLP 适合简单、浅层的数据结构
SSZ 适合大型、结构化、可验证的树形数据
RLP编码
简介
递归长度前缀,RLP (Recursive Length Prefix) ,一种以太坊中采用的编码方式,作用是对对象进行序列化和反序列化
定义
RLP 编码只支持两种基本类型:
- 字符串(string)
- 本质为字节组 (bytes)
- 列表(list)
- RLP 基本类型的有序集合
- list 可以包含 string
- list 可以包含 list (递归)
前缀空间划分:
RLP 使用 1个字节 (8 bit) 来区分类型与长度信息
[0x00, 0x7f] 单字节(值即编码) // "c"
[0x80, 0xbf] 字符串
[0x80, 0xb7] 短字符串(长度0-55) // "cat"
[0xb8, 0xbf] 长字符串(长度>=56)
[0xc0, 0xff] 列表
[0xc0, 0xf7] 短列表(0-55) // ["cat", "dog"]
[0xf8, 0xff] 长列表(>=56)
RLP 编码规则如下:
// ========================================================
// 1.对于 [0x00, 0x7f]范围内的单个字节, RLP编码内容就是字节内容本身
// bytedata
"c"
b'c'
63
// ========================================================
// 2.如果是一个 0-55 字节长的字符串,则 RLP 编码由 0x80 加上字符串长度,再拼接上字符串二进制内容
// 0x80+len, bytedata
"cat"
b'\x83cat'
83 63 61 74
// ========================================================
// 3.如果字符串超过 55 字节,则由 0xb7 加上字符串长度字节数,再拼接上字符串长度编码,再拼接上字符串二进制内容
// 0xb7+len(len), len, bytedata
"0"*1024
b'\xb9' + b'\x04\x00' + b'00'*1024
b9 0400 303030303030...
// ========================================================
// 4.如果列表所有项组合长度是 0-55 字节内,则由 0xc0 加上所有项的 RLP 编码串联长度字节,再拼接所有项的 RLP 编码
// 0xc0+len(rlp_all)
["cat", "dog"]
b'\xc8\x83cat\x83dog'
c8 83636174 83646f67
["cat", "dog", ["ab","cd"], "ef"]
b'\xd2 \x83cat\x83dog \xc6\x82ab\x82cd \x82ef'
// ========================================================
// 5.如果列表内容超过 55 字节,则由 0xf7 加上所有项的 RLP 编码串联长度字节,再拼接所有项的 RLP 编码
// 0xf7+len(len(rlp_all)), len, bytedata
...
测试 python 规范 & 深入理解编码设计
以太坊对于 RLP 编码的规范在:ethereum-rlp
相比 go-ethereum 的实现,python 规范的实现更加简洁易懂

理解代码后,可自己实现写个小demo(这里只写了 encode 编码对字符串和列表类型的部分)
#coding: utf-8
"""
@Author: 0xhunya
@Date: 2025-12-22
@Description: test poc for ethereum-rlp
"""
TEST_CASES = {
"TEST_INT_SHORT": 64,
"TEST_INT_LONG": 256,
"TEST_STRING_NULL": "",
"TEST_STRING_ONE": "c",
"TEST_STRING_SHORT": "cat",
"TEST_STRING_LONG": "0"*1024,
"TEST_LIST_NULL": [],
"TEST_LIST_SHORT": ["cat", "dog"],
"TEST_LIST_SHORT_NEST": ["cat", "dog", ["ab", "cd"], "ef"]
}
def encodeBytes(raw):
len_raw = len(raw)
if len_raw == 1:
return raw
elif len_raw < 56:
return bytes([0x80+len_raw]) + raw
else:
len_len_val = (len_raw.bit_length() + 7) // 8 # 字节长度
return (
bytes([0xb7 + len_len_val]) +
len_raw.to_bytes(len_len_val) +
raw
)
def encodeList(raw):
join_enc_raw = b"".join(encode(i) for i in raw)
len_join_enc_raw = len(join_enc_raw)
print(len_join_enc_raw)
if len_join_enc_raw < 56:
return bytes([0xc0 + len_join_enc_raw]) + join_enc_raw
else:
len_len_join_enc_raw = (len_join_enc_raw.bit_length() + 7) // 8 # 字节长度
return (
bytes([0xf7 + len_len_join_enc_raw]) +
len_join_enc_raw.to_bytes(len_len_join_enc_raw) +
join_enc_raw
)
def encode(data):
if type(data) == int:
return encodeBytes(data.to_bytes((data.bit_length() + 7) // 8))
elif type(data) == str:
return encodeBytes(data.encode())
elif type(data) == list:
return encodeList(data)
else:
return "Not Support Now"
def main():
for testType,testData in TEST_CASES.items():
print("\n==================== testing %s ====================" % testType)
print("data: %s" % testData)
res = encode(testData)
print("encode: %s" % res)
main()
可以通过将自己实现的函数逻辑替换 src/rlp.py 中的对应函数进行测试,看是否能通过测试规范
测试 encodeList 函数,替换 encode_sequence

测试 encodeBytes 函数,替换 encode_bytes

发现有 15 项测试未通过,仔细对比函数逻辑可以发现,在对单字符的判断里缺少了校验该单字符需在 128(0x80) 以内
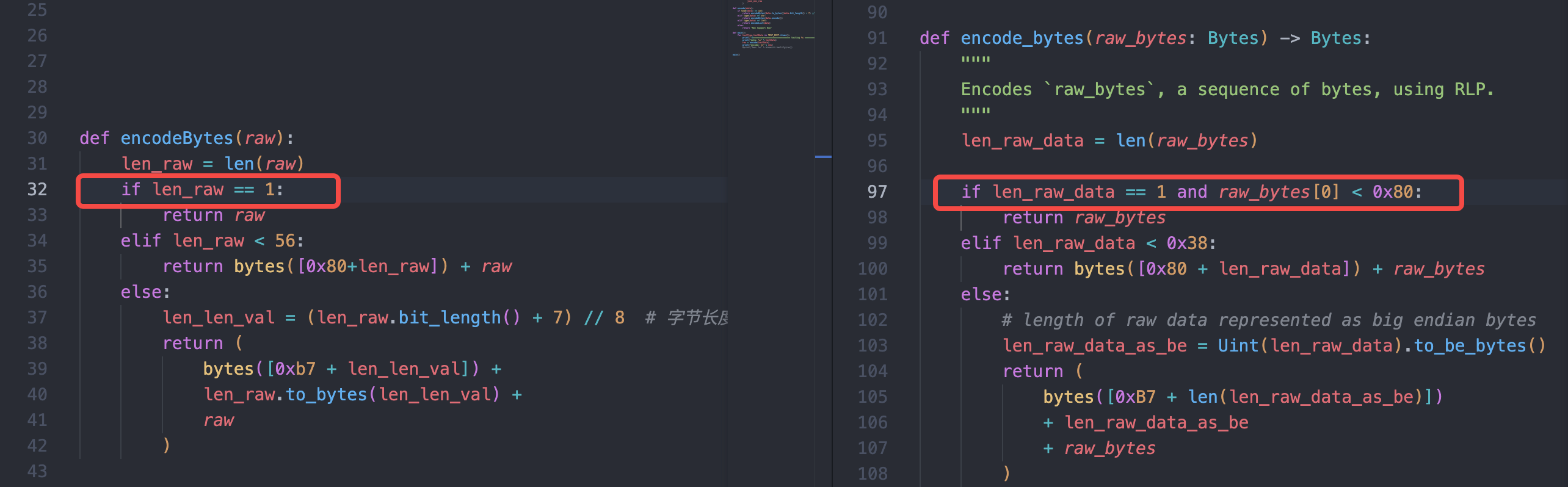
完善校验 and row[0] < 128 ,再跑一遍,测试通过

细节思考 & 深入理解
为什么会有
< 0x80的校验?为什么超过 128 的整型数值也会需要额外前缀标识?
因为 RLP 编码设计中基本类型只有 字符串 (string) 和 列表 (list),对于整型并没有单独的规则,那么设计上对于整型的编码是当作字符串来处理的(转为大端序字节串)
我们回到前缀空间的划分部分,可以看到最前面的 0x00-0x80 部分是直接表示的单字符值本身,这也对应标准的 ASCII 码表,可以完美覆盖。那么如果整型超过 128 (0x80) 就超过了单字节可表示的范围了,就需要增加前缀来表示,以确保编码的唯一性
这样的话,那不是整型和字符串的编码结果几乎是重合的,也就是每一个字符串都能找到一个整型使他们的编码结果完全一致
比如 c 和 99,编码结果都是 0x63、cat 和 6513012 ,编码结果都是 0x83636174
这也还是回到了 RLP 编码的设计初衷,是一个无类型的序列化格式,不管字符串还是整型,都是针对数据本质的字节序列进行编码,RLP 编码的唯一性是指同一个“字节序列”只有一个合法的 RLP 编码形式,而解码时需要考虑这些数据的类型信息的是上层协议需要做的,0x63 如果需要解码为字符串就是 c,如果需要解码为整型就是 99
go-ethereum 实现
go-ethereum 中的 RLP 实现在 go-ethereum/rlp 目录下 ,相比 python 规范多了非常多的工程优化
核心实现集中在 encode.go 、 encodeBuffer.go 、 decode.go 中
先看 encode.go 文件,首先全局定义了最特殊的两个数据 空字符串 和 空列表 的编码结果,然后定义了 Encoder 接口类型

Encoder 接口主要用于 包外其他模块实现接口 和 包内通过反射实现对各种不同数据类型进行高效率编码
接着是 Encode 、 EncodeToBytes 、 EncodeToReader 三个主要编码入口函数
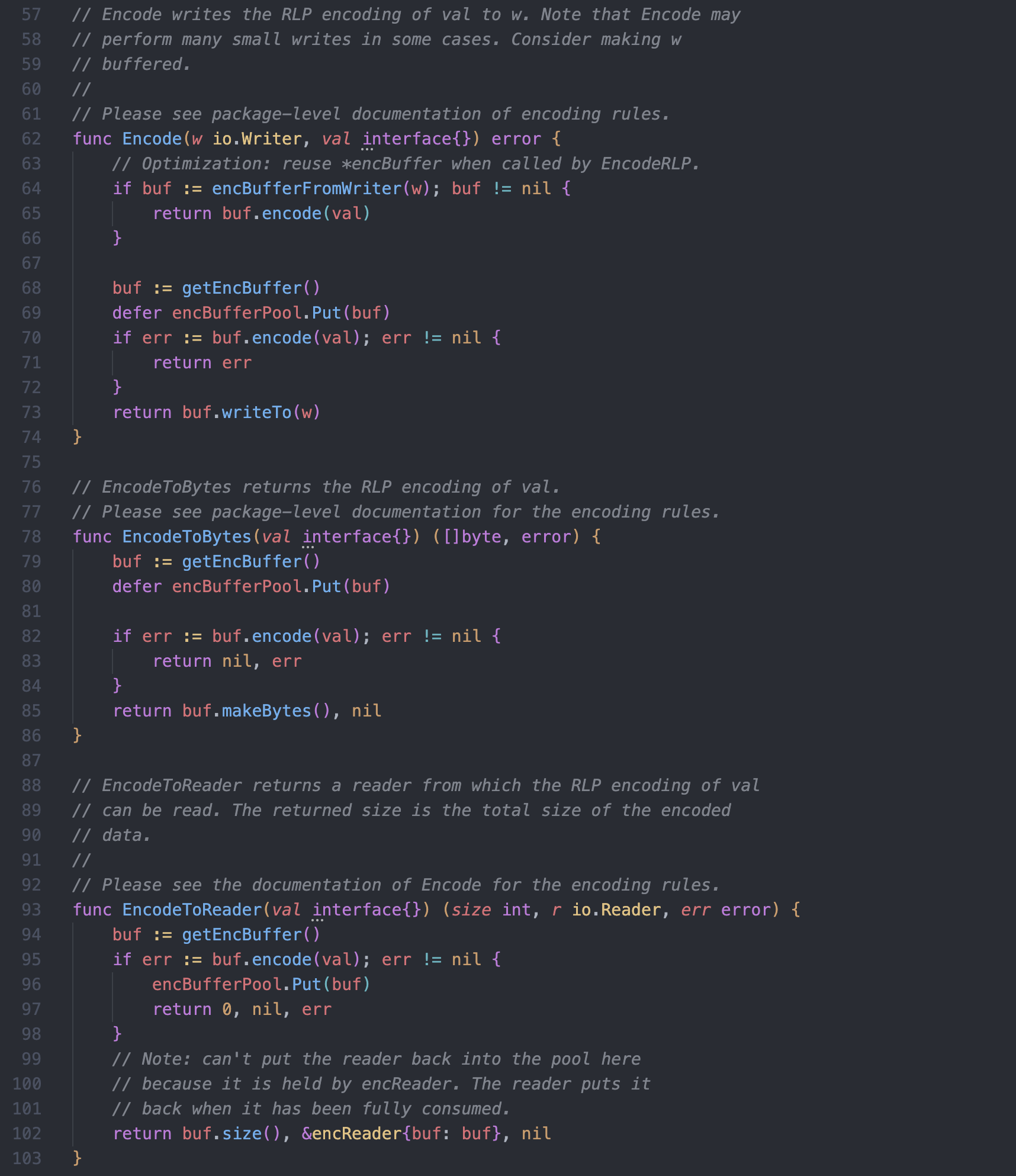
主要逻辑都是通过 getEncBuffer() 函数从 encBufferPool 编码缓存池中获取 encBuffer 编码缓存数据,再调用它的 encode 函数进行编码,最后按需输出到 io.Writer 、[]byte 、 io.Reader ,所以编码的核心逻辑是在 encBuffer.go 中的 encBuffer 数据结构中,encode.go 文件中剩下的内容就主要是些反射类型处理和辅助工具类的函数
那么我们来看 encBuffer.go 文件,首先定义了 encBuffer 结构体和 encBufferPool 缓存池
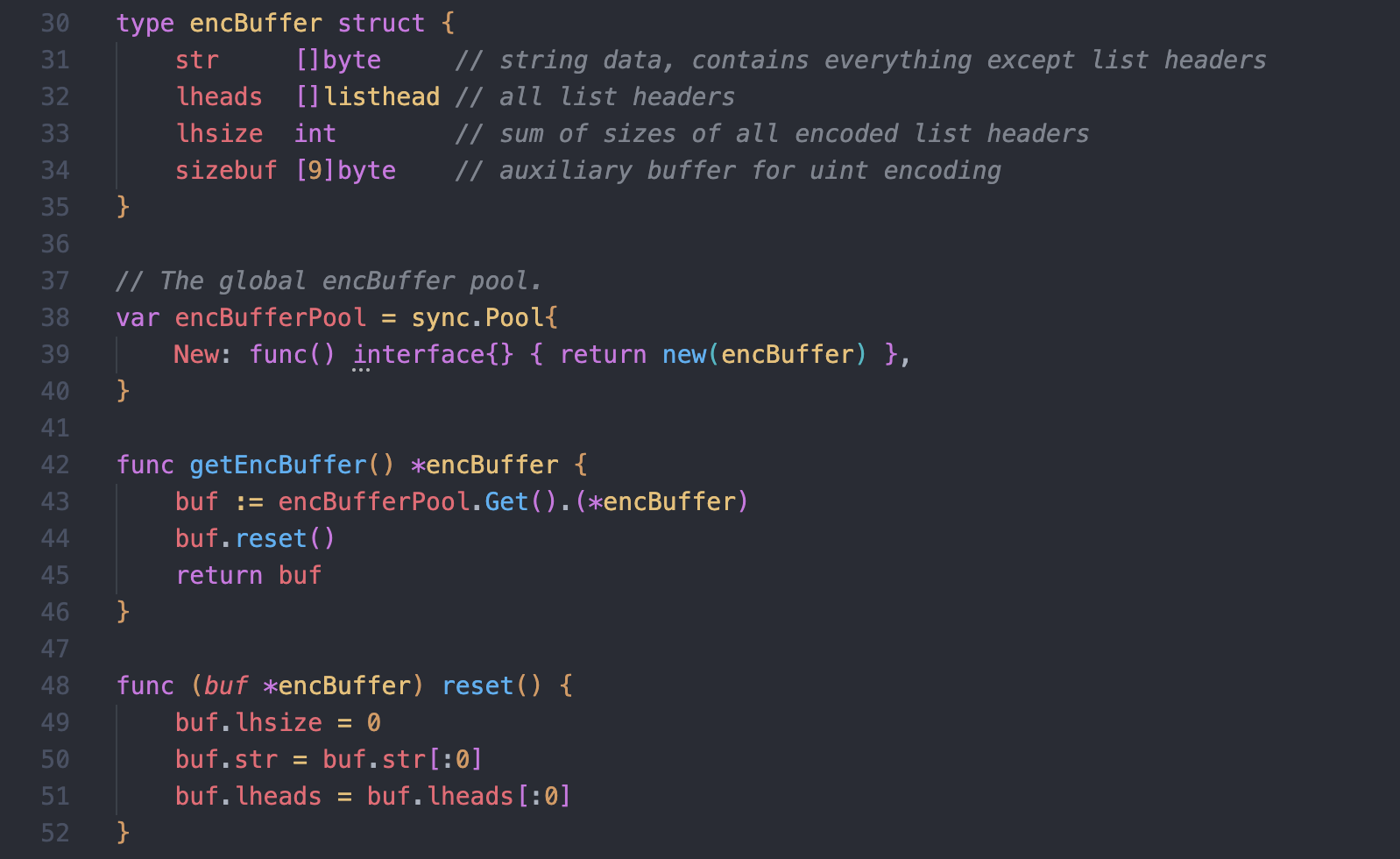
encBuffer 结构体拆分了这样几个字段
/// file: go-ethereum/rlp/encbuffer.go
type encBuffer struct {
str []byte // 字符串数据, 包括除列表头以外的所有内容
lheads []listhead // 列表头数组,包含所有的列表头
lhsize int // 所有编码后的列表头长度总和
sizebuf [9]byte // 整型编码的辅助缓存,主要存放 前缀头(1 byte) + 长度的长度(8 byte)
}
其中 listhead 在 encode.go 中定义

encBuffer 会通过 listhead 记录编码数据中每一个 list 的起始位置和总长度 ,这样通过一次遍历就能完成数据的编码
采用 sync.Pool 缓存池以及 encBuffer 的结构设计,均是为了提高编码效率的工程优化,因为 geth 执行层的底层数据结构都会采用 RLP 编码,调用频率极高
紧接着是 makeBytes 、 copyTo 、 writeTo 函数

前面能看到在 encode.go 文件中的 EncodeToBytes 函数最后就是调用 encBuffer 的 makeBytes 函数输出 []byte,这里可以看到 makeBytes 函数是调用的 copyTo 函数,而 writeTo 函数和 copyTo 逻辑一致,只是最后输出写入 io.Writer,而 copyTo 输出返回 []byte
copyTo 和 writeTo 的核心逻辑都是:
- 遍历
buf.lheads列表头数组,先写入第一个 list 前的字符串数据编码(如果有);- 记录位置,循环写入列表头数组中记录的每个列表数据编码;
- 写入最后一个 list 后的字符串数据编码(如果有)
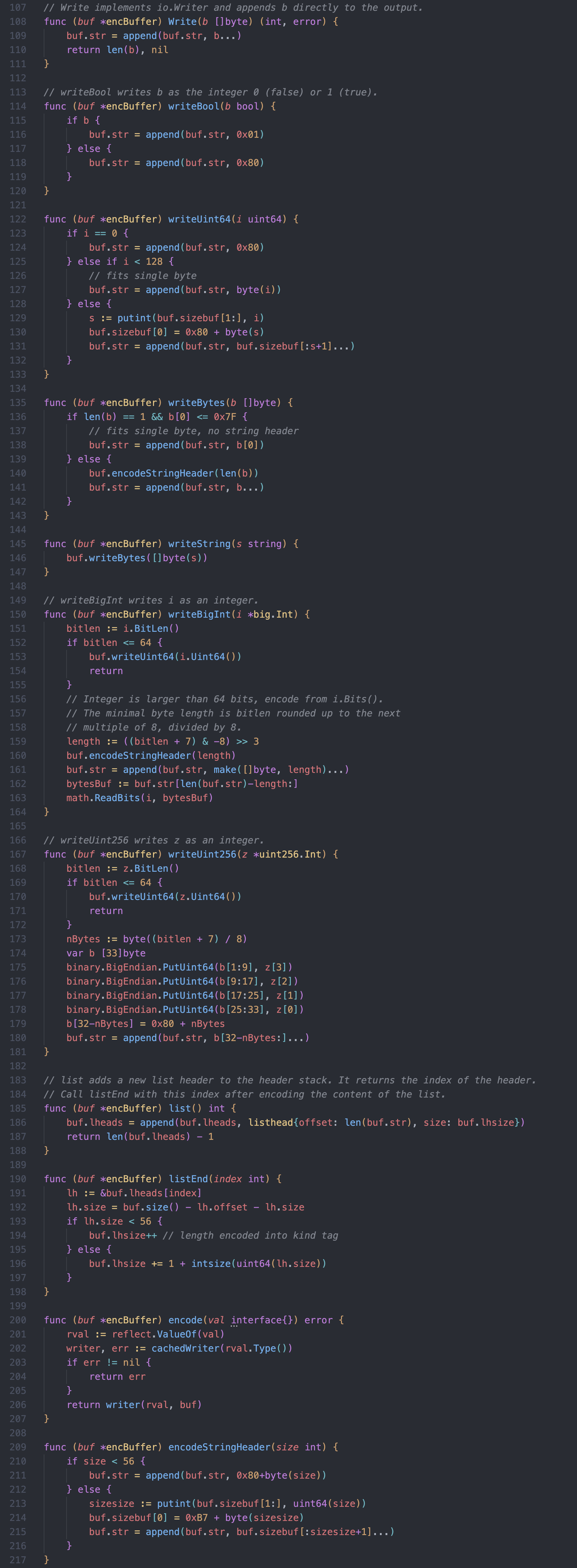
再后面就是 encBuffer 的编码核心
编码单一数据类型写入的一系列
write类函数处理 list 类型写入的
list和listEnd函数通过反射获取类型相应
writer写入的encode函数编码字符串前缀头的
encodeStringHeader函数
这里就能看到熟悉的 RLP 编码规则
总结
ethereum 的 RLP 编码,在 python 规范中,通过函数递归实现,简洁高效地展示了 RLP 编码的规则;而在 go-ethereum 中,则通过 encBuffer 缓存结构实现,以类似流式编码的方式实现了高效率高性能的 RLP 编码工程。